生成AIからエージェントAIへの進化と企業導入のポイントコラム
公開日:2025年12月4日

社内のFAQ応答や文書検索、要約といった“補助的な作業”を支える役割で使われることが多かった生成AIですが、最近ではその立ち位置が変わりつつあります。AIは「答えを提供する存在」から、「人とともに働き、判断を支援するパートナー」へと進化しています。この変化の中心にあるのがAIエージェントという考え方です。人からの指示を待つだけでなく、目的に応じて自律的に情報を集め、判断し、行動を起こす。そんな“動くAI”が注目を集めています。
では、このAIエージェントとは実際どのようなものなのか。そして、安全かつ現実的に導入・運用するためには、どんな課題があるのでしょうか。
本コラムでは、生成AIからAIエージェントへの進化を整理しながら、その仕組みや特長、活用の可能性を解説します。さらに、企業が導入を進める上で直面する課題と、それを乗り越えるためのアプローチについてもご紹介します。
生成AI活用の新たなステージ―AIエージェントの台頭
ここ数年で、生成AIは一気に身近な存在になりました。文章の要約や、社内FAQへの対応など、私たちの業務を支える“サポート役”として活用される場面が増えています。しかし今、その生成AIが単なるチャットツールや文章作成の域を超え、自ら考え、判断し、行動する「AIエージェント」へ進化しつつあります。
生成AIからAIエージェントへの進化
従来の生成AIは、「質問に答える」「文章を作成する」といった受け身の役割が中心でした。いわば“賢い相談相手”としての立ち位置です。一方、AIエージェントは、目的を理解し、自ら情報を集め、判断し、行動を起こすことができます。たとえば、営業部門で「次の商談準備をして」と指示すれば、AIエージェントは顧客情報を収集し、過去の商談履歴や競合情報を整理した上で、提案書の下書きまで自動で作成します。ただ答えるだけでなく、目的達成のために“自走”する点がAIエージェントの特長です。
この進化により、AIは人の「補助ツール」から「共に働くチームメンバー」へと役割を変えつつあります。
実際、米国を中心に、AIエージェントの考え方を取り入れたサービスや機能が次々と登場しています。
たとえば、Microsoftの「Copilot」では、メールやドキュメント等のアプリ群にAIエージェントを統合し、ユーザーの目的に応じて複数アプリを横断的に操作する仕組みを実現しています。
AIエージェントの特長と強み
AIエージェントの本質は、「目的を理解し、状況に応じて自ら動く」ことにあります。その仕組みを支えているのが、自律性・連携性・学習性の3つの特長です。それぞれの役割を少し掘り下げて見てみましょう。
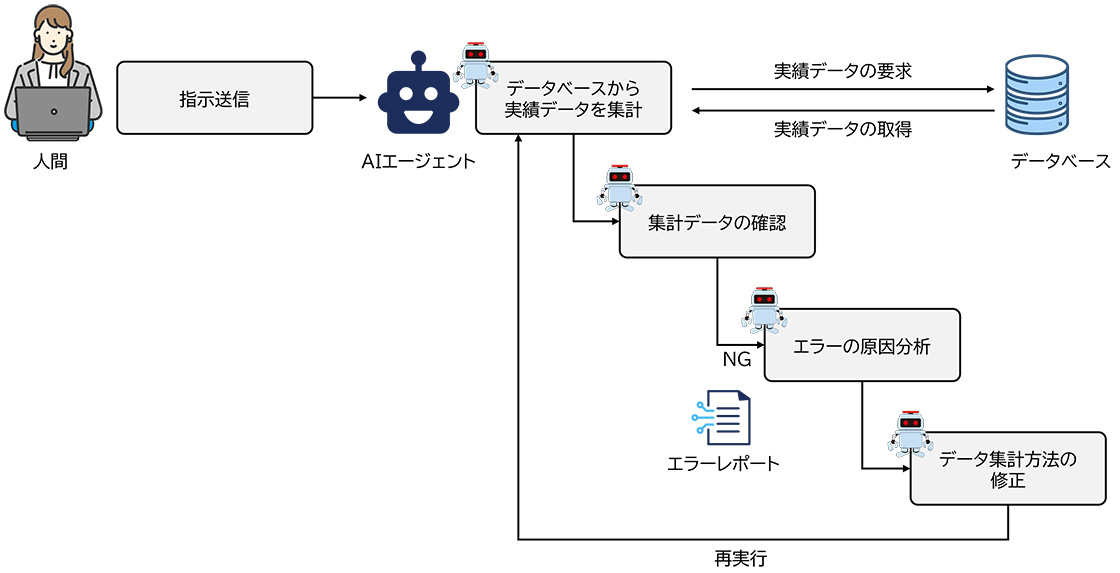
自律性―結果を踏まえて次の行動を判断する
AIエージェントの「自律的に動く」とは、何も勝手に動き出すという意味ではありません。
実際には、ある目的を与えられたAIが、事前に与えられたツール(ナレッジデータやデータベース接続)を使って自ら考えた各ステップの処理を実行し、ステップ毎に結果を確認しながら、次に取るべき行動を自分で選択するように動きます。
たとえば、「月次の工場別の製造数量を集計して傾向をまとめて報告してください」という指示を出すと、AIはまずデータベースから製造数量データを取得→データが正常に取得できたか確認・判断→工場別の月次製造数量を集計→正常にデータ集計を終えたか確認・判断→集計結果を元に分析しレポートを作成する→結果を出力する、という流れを繰り返します。
つまり、各ステップで得られた結果をもとに、「次に何をすべきか」を再び生成AIが判断し、必要に応じて処理を分岐させるというように、人が途中で手を挟まなくても進行できる“処理フロー”を持っているのです。こうした「結果を踏まえて次を決める」設計が、AIエージェントに“自律的に動いているように見える”動きをもたらしています。
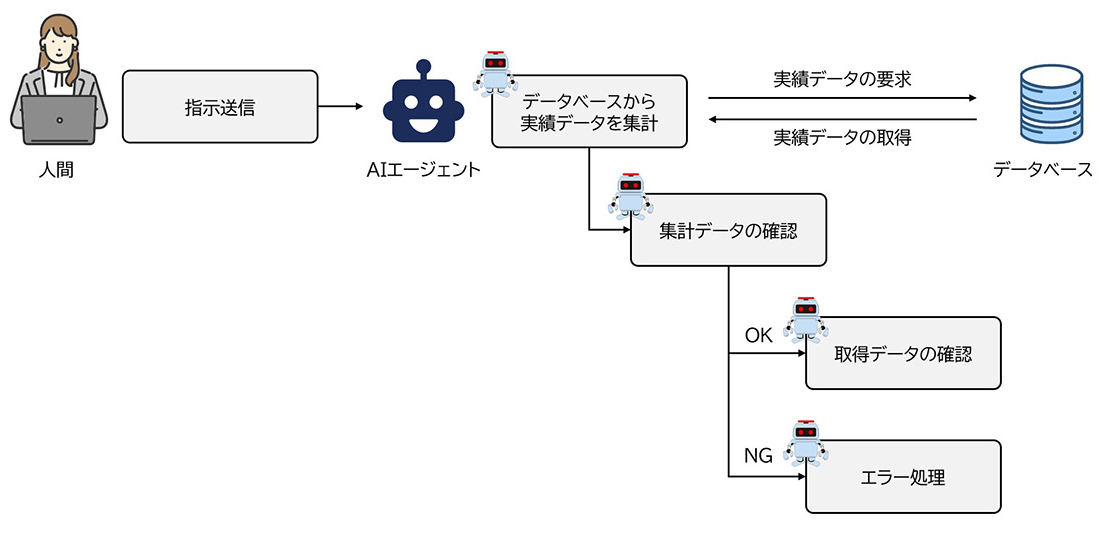
連携性―システムをまたいで情報を活用する
AIエージェントのもう一つの特長が、外部システムやツールとの連携です。単に回答を生成するだけでなく、メール、スプレッドシート、チャットツールなどとつながり、情報の取得・登録・通知といった一連の操作を自動で実行します(下図)。このように複数のアプリを横断してタスクを実行することで、AIは「考えるだけでなく、動いて成果を出す」存在になっています。
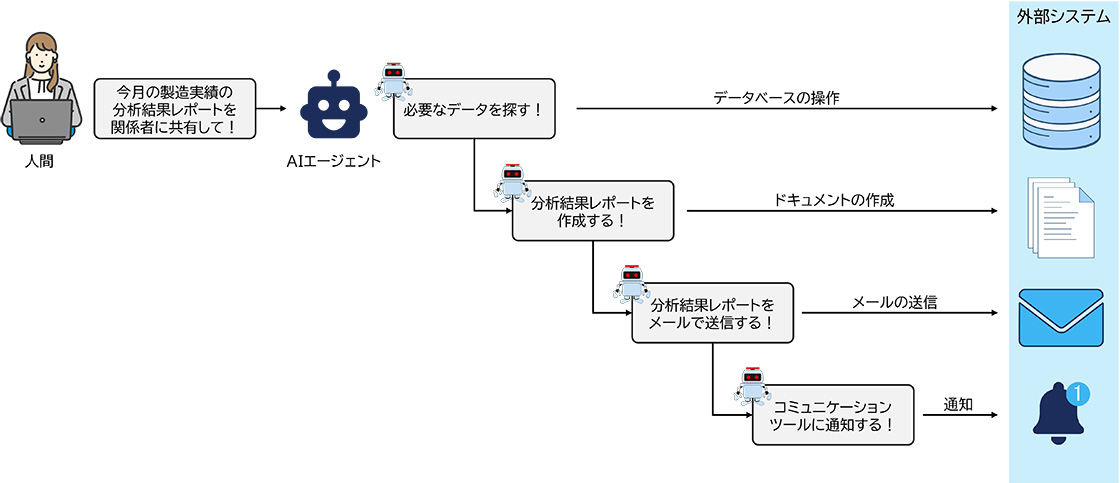
学習性―経験をもとに行動を改善する
AIエージェントは、行動を通じて得た結果をもとに、次の判断をより良くする仕組みを備えています。
ここで言う“学習”とは、実行中に得られた情報(成功・失敗・エラーなど)をフィードバックし、その内容を次の推論や判断に反映していくプロセスのことです。たとえば、処理中にエラーが発生した場合、AIはエラー内容を生成AIに渡して原因を推定させ、修正を加えた上で再処理を行うことができます。
こうした「経験を踏まえて行動を調整する」流れをReflection(自己改善)ループと呼び、この仕組みによってAIエージェントは処理を重ねるごとに精度を高めていきます。
このように、AIエージェントは単なる会話型AIではなく、「思考→判断→行動」を一連の流れで行える新しいAIの形です。
業務シーン別のAIエージェント活用ユースケース
AIエージェントは、業種を問わず多様な業務に応用できます。ここでは、いくつかの活用シーンをイメージとして紹介します。

営業・マーケティング分野
顧客データや購買履歴をもとに次の提案内容を自動過去の商談内容から「次に送るべきメール」や「会話トピック」まで導き出すことができます。
バックオフィス分野
契約書のレビューや稟議書の下書きを自動生成。
条文チェックや過去の承認履歴をもとに、リスクのある箇所を自動で指摘します。
カスタマーサクセス分野
問い合わせを受けると、「顧客対応AIエージェント」が社内マニュアルやナレッジベースを検索し、最適な回答を生成。
必要に応じて担当部署へエスカレーションするなど、業務フロー全体を支援します。
各ユースケースにおいて、それぞれが異なる役割を持つ複数のエージェントが連携して複雑な業務を遂行していく、という考え方が重要なポイントになります。例えば、「顧客対応AIエージェント」では、以下のようなエージェントが各ステップでタスクを自律的に遂行していくことになるでしょう。
- 受付エージェント:顧客からの問い合わせをリアルタイムで受け付け、内容を瞬時に分類する。
- 調査エージェント:分類された内容に基づき、膨大な社内ドキュメントや過去の対応履歴を検索・参照する。
- 解決策立案エージェント:調査結果を深く分析し、複雑なロジックを組み立て、最適な解決策を導き出す。
- 最終応答生成エージェント:立案された解決策を、顧客にとって自然で分かりやすい言葉に整形する。
こうした活用はまだ始まったばかりですが、今後は企業のあらゆる部門で「AIが自ら動く」仕組みが当たり前になっていくかもしれません。
AIエージェント導入における課題
AIエージェントの導入は、業務効率化や意思決定支援の面で大きな可能性を秘めています。一方で、システムとして安定的に運用していくためには、データ・モデル・運用体制という3つの観点で、いくつかの課題を乗り越える必要があります。ここでは、導入時に特に重要となる3つのポイントを整理します。
データ品質管理―情報の鮮度と正確さをどう保つか
AIエージェントの判断や回答の精度は、参照するデータの品質に大きく左右されます。
RAG(Retrieval-Augmented-Generation:検索拡張生成)のように、生成AIが自社のデータベースや文書などを参照し、回答を生成する場合、生成AIが参照する文書情報などは定期的に更新・検証する仕組みが欠かせません。
古い文書や誤った情報が混在していると、生成AIが誤った結論を導き出してしまうリスクがあるため、社内規程やFAQのように内容が頻繁に変わる情報は、自動更新や変更履歴の追跡を設けるなど、情報の鮮度を保つ工夫が求められます。
また、生成AIは“一見もっともらしいが誤った内容”を生成してしまう「ハルシネーション」と呼ばれる現象を起こすことがあります。このため、誤情報をそのまま出力してしまう「ハルシネーション」を防ぐファクトチェックの仕組みも重要です
モデル選定―利用ケースに最適なAIを選ぶ
AIエージェントの中心となるLLM(Large Language Models:大規模言語モデル)は、そのエージェントの役割によって求められる特性(コスト、応答速度、扱える情報量、思考力、など)が異なるため、複数のエージェントが連携して業務を遂行するマルチエージェント・システムを構成する全てのエージェントを単一のLLMで賄う、という考え方は多くの場合通用しません。
このため、エージェント・システム開発時には複数のLLMを比較・検証し、実際の業務データを用いて性能を評価するプロセスが欠かせません。最近では、DataRobot LLM Gatewayのように複数LLMの性能をワンストップで比較・評価することが可能なツールや、複数の生成AIに並列で処理を行わせることができるツールなども登場しています。こうした仕組みを活用することで、自社の利用ケースに最もフィットするLLMをエージェント毎に選定し、利用することが可能になります。
運用ガバナンス―継続的な監視と改善を仕組み化する
AIエージェントは導入して終わりではなく、運用を通じて品質を維持・改善することが重要です。
応答の精度、コスト、処理速度、利用頻度といった指標を継続的に監視し、問題があればモデルやデータを更新するという改善サイクルを設ける必要があります。
また、生成AIが社内データにアクセスして動作する場合、アクセス権限の制御やログの取得など、セキュリティ・コンプライアンス面のガバナンスも欠かせません。
これらをシステム的に担保することで、安全かつ信頼性の高いAIエージェント運用を実現できます。
AIエージェントをビジネス現場に安全に導入するには、「正しいデータを使い、適切なモデルを選び、継続的に改善する」ことが重要になります。
DataRobotが支えるAIエージェント基盤
AIエージェントを安全かつ継続的に運用していくためには、データの管理・モデルの選定・品質の監視といった仕組みを一元的に支える基盤が欠かせません。その実現を後押しするのが、生成AIと予測AIを統合し、ビジネス成果を創出するAIエージェントを迅速に構築・運用・統制できるエージェントワークフォースプラットフォーム「DataRobot」です。ここでは、AIエージェントの構築・運用を支えるDataRobotの特長を3つご紹介します。
ノーコードで構築できる生成AIの知識補完基盤
AIエージェントの思考力パフォーマンスは「どのようなデータを学習・参照できるか」強く依存します。
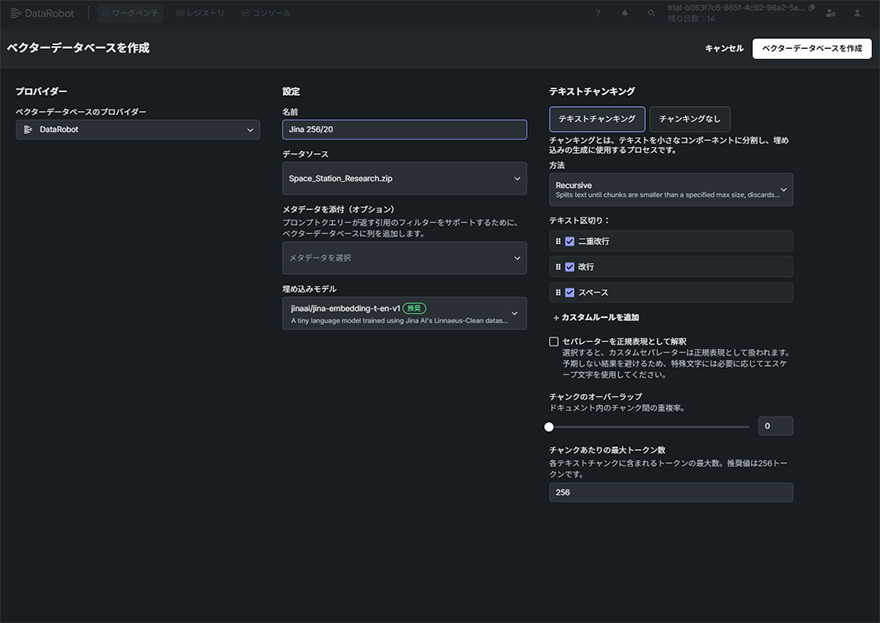
DataRobotでは、RAG(検索拡張生成)上で生成AIが検索し追加知識として扱うデータを、ベクトル化し保持するためのベクターデータベースをノーコードで構築することが可能です。これにより、どなたでも簡単にマニュアルや社内文書など、その企業にとってのユニークな情報を生成AIに追加知識として与えることができます。
専門的なコーディングや環境構築は不要で、画面上の操作だけでデータのアップロード、生成AIの基盤モデルや埋め込みモデルの選択、チャンク(文書分割)設定などを行えます。
マルチLLMの比較
前述のように、マルチエージェント・システムを構築する際に悩ましいのが、「どのLLMを使うのが最適か」というモデル選定です。
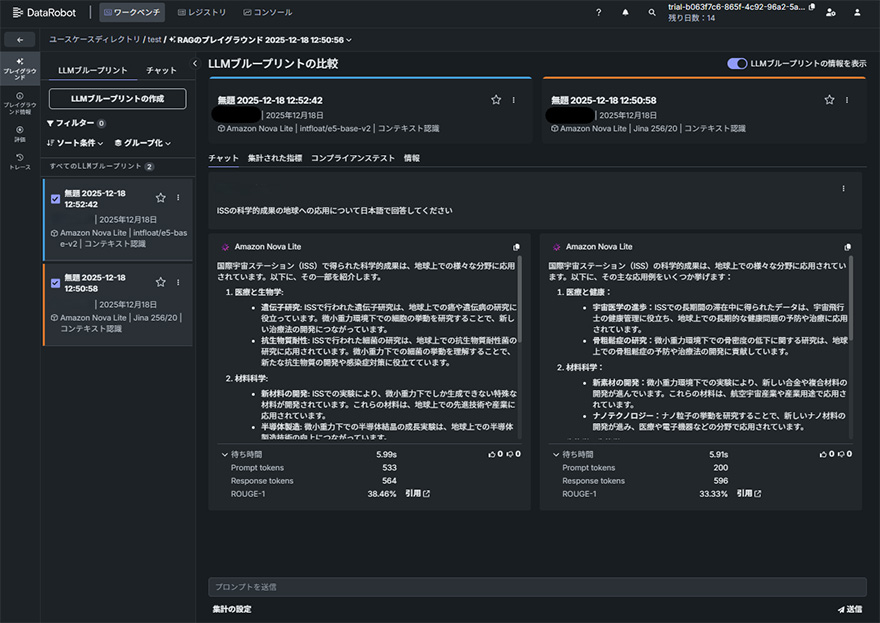
DataRobotでは、ベクターデータベースを作成する際に、ユーザーのアップロードした文書などの情報をベクトル化する際に利用する”埋め込みモデル”と、回答を生成する際に利用する”生成AIモデル(LLM)”を組み合わせRAGの設計図となる”ブループリント”として作成することができます。
また、このブループリントを、横並びで比較することで、設定されている埋め込みモデルと生成AIモデルの組み合わせ毎に回答生成の内容を確認し、さらに、回答に要した時間や、ROUGE-1(LLMの回答が関連コンテキストとして提供された引用とどの程度類似しているか)のスコアなど定量的に品質を確認できます。
ユースケースに最も適したモデル構成を定量的に選定でき、「どのLLMを使うか」だけでなく「どの組み合わせが最適か」を判断できるようになります。
デプロイしたLLMの監視と継続的運用
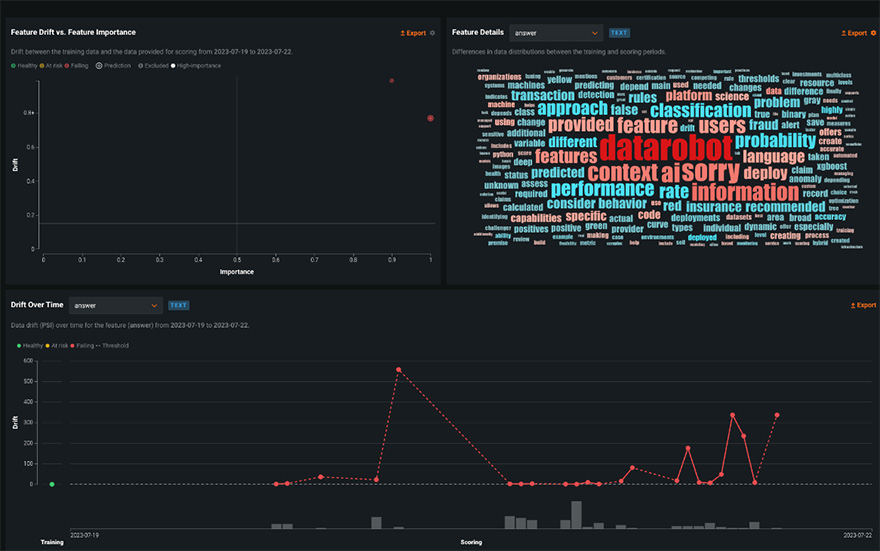
ブループリントをデプロイ、利用し、安定的に運用する上で欠かせないのが、システム内で使用されるLLMからの出力品質や運用コストを継続的にモニタリングする仕組みです。
DataRobotでは、従来のMLOps(予測モデル運用管理)を拡張したLLMの運用監視機能を提供しています。
この機能により、生成AIが回答生成にかかったコストや時間、データのドリフトなど監視することが可能です。
これらの実運用時のデータを分析し改善することで、“作って終わり”ではなく“改善しながら運用する”AIを実現できます。
AIエージェントをPoC止まりにせず、業務プロセスに導入して初めてRoIを得られることは自明です。しかし複数のエージェントが連携して複雑なステップで業務を遂行するマルチエージェントシステムを実際に運用するためには、このような管理・監視の仕組みが必須です。MLO@s/LLMOpsによってエージェントシステム内で稼働する複数モデルの品質管理がなされていないと、AIが実業務プロセスで大きな問題を起こすリスクを未然に摘み取り、コントロールすることはできません。

さいごに
本稿では、生成AIの進化からAIエージェントの登場までの流れを整理し、導入・運用における課題と、それを支える基盤について紹介しました。
AIエージェントの導入には、データ品質の確保、モデルの選定、運用体制の整備といった検討すべき要素が多く存在します。しかし、それらの課題を一つずつ整理し、環境を整えることで、業務効率化や判断支援など、具体的な成果につなげることができます。AIエージェントは、まだ新しい技術領域ではありますが、今後の企業活動において重要な役割を担っていくと考えられます。
このコラムが、AIエージェント導入に向けた基盤づくりや運用体制の検討を進める際の参考となれば幸いです。
筆者紹介

大竹 智礼(おおたけ とものり)
キヤノンITソリューションズ株式会社 デジタルビジネス統括本部
デジタルソリューション開発本部 デジタルビジネス推進部
略歴
2017年 食品メーカーでの食品製造・生産技術・DX推進などの業務に従事。プロセス工程の計装制御設計やデジタル化ツールの利活用による製造工程の自動化効率化改善・ロス改善の活動に取り組む。
2023年 キヤノンITソリューションズに入社。データサイエンティスト業務に従事。
保有資格 基本情報技術者試験
関連する製品・ソリューション・サービス
- AI(人工知能)
- AIの活用が進み、AIを使ったソリューションが身近になる一方、実用化にまで至らないAIプロジェクトも数多く存在します。
キヤノンITソリューションズでは、長年にわたるSIerとしての経験と業務知識、さらにはR&D部門での研究によって得た知識や、商品開発の技術を駆使して、お客さまの課題解決にAIを活用した支援を行います。
- DataRobot
-
企業がAIを活用して継続的な成果をあげるためには、以下の3つに関する深い知識・知見を有した人材が必要と言われています。
-
対象となる事業ドメイン・ビジネス
-
統計学や機械学習を含むデータサイエンス
-
データとシステムに強いITエンジニア
-
- しかし、これらの異なる領域に精通した人材の確保や育成は非常に難しいのが実情です。
-
DataRobotとは、エージェントシステムの構成要素である生成AI/予測AIの開発・管理・監視をエンドツーエンドで一元化するAIプラットフォームです。その機能の1つとして高度で高速なモデル開発を実現する機械学習自動化(AutoML)ソリューションを提供しています。この機能により日々更新される数千のアルゴリズムの中からデータと目的に合った最適な機械学習の予測モデルを自動生成することが可能です。
これまでのデータサイエンティストは、相当な時間と試行錯誤を繰り返し予測モデルを開発していましたが、「DataRobot」により学習データを用意するだけで簡単に機械学習を始めることができます。 - ただし、AIをビジネスに活用するには、“何を予測するか”、“予測によってビジネスをどう変えていくか”、“AIの予測結果を基にどういった行動を実行するか”、というAI特有の課題設定や具体的なゴール設定をお客さま自身で行っていただく事が必要です。AIの予測結果をビジネスプロセスの一部としてシステムに組み込むことは、継続的な成果の獲得につながります。
- キヤノンITソリューションズは、長年システムインテグレーターとして培ったシステム企画・開発ノウハウ、プロジェクト管理経験を基に、専門の知識を有したデータサイエンティストとコンサルタントが、お客さま自らがAIを活用できるよう、機械学習の課題設定からシステム連携まで一貫してご支援いたします。