音声認識ツールWhisperの固有名詞の認識精度向上に向けたチューニング テクニカルレポート

公開日:2026年2月12日
R&D本部 言語処理技術部の新です。
Whisperは、OpenAI社が公開しているオープンソース音声認識ツールで、日本語を含むさまざまな言語で高い認識精度を達成しています。Whisperの活用例として、会議音声の文字起こしなどの業務支援が挙げられます。
一方、Whisperには、固有名詞の認識精度が低いという課題があります。会議音声の文字起こしでは、社名や人名などの固有名詞を正しく文字起こしすることが困難であり、誤認識の修正に労力を費やしてしまうことが起こりえます。この課題を解決する手段として、Whisperのチューニングが挙げられます。認識させたい単語の音声データを用いてWhisperをチューニングすることで、当該単語の認識精度を向上できることが知られています。本稿では、Whisperチューニングの検証結果について解説します。
特定の単語を認識できるようにするためのWhisperチューニング方法
Whisperにある単語を学習させるには、「単語の音声データ(どのように発音するか)」と「単語の文字列(どのように表記するか)」の2つの情報が必要です。音声データは、サウンドレコーダー(Windows標準アプリ)などの録音アプリを利用して自分の声で収録することもできますが、大量の単語を学習させたい場合は音声合成のテキスト読み上げツールを利用する方法が便利です。音声合成を利用する場合は、単語の読み仮名の情報が必要となります。これらの情報があれば、単語の学習を行えます。
Whisperチューニングの検証
Whisperチューニングについて、以下の2点について知見を得るため、検証を行いました。
- 単語はいくつまで学習させることができるのか
- チューニング後モデルはどのような誤りをすることが多いのか
検証設定
実行環境
今回の検証では、GPUとしてNVIDIA GeForce RTX 4090(24GB)1枚を使用しました。
モデル
ベースモデルには、Huggingfaceで公開されているWhisper-large-v3モデルを使用しました。これはパラメータ数1.54B程度であり、今回の実行環境でも十分に学習/推論ができます。
データセット
今回の検証では、Whisperに学習させる単語の収集元として、国税庁が公開している全国の法人一覧データ(2025年6月30日更新分)を使用しました。このデータには、全国の法人の名前と読み仮名の情報が含まれています(一部、読み仮名の情報がないデータもあります)。このうち、読み仮名が5文字以上などの条件に全て当てはまるデータを抽出して利用しました。
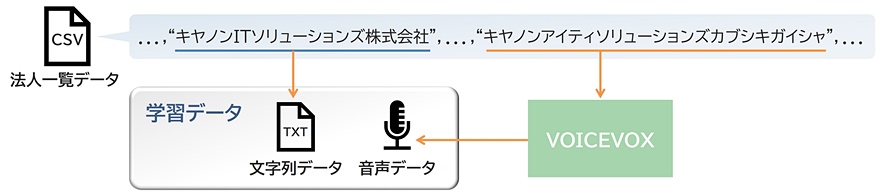
次に、得られた法人データの読み仮名情報を用いて合成音声データを作成しました。合成音声の作成にはVOICEVOXを利用しました。VOICEVOXはさまざまなキャラクターによるテキスト読み上げを利用できる、商用利用可能なツールです(一部キャラクターは権利元企業への事前確認が必要です)。このようにして得られた合成音声データに対して、法人名を正解の文字起こしデータとすることで、学習用のデータとしました(図1)。
また、ベースモデルで既に正解できるデータを追加で学習すると、過学習となってモデルの性能が低下してしまうおそれがあります。そのような事態を避けるため、チューニング実施前に、作成した合成音声データをベースモデルに与えて文字起こし結果を確認しました。文字起こしの結果と正解の法人名が一致していれば、そのデータは学習データセットから除外しました。
このようにして、最終的に10,000件の学習データセットを作成し、データセットの読み仮名の文字数は平均9.192文字となりました。検証では、学習データセットの件数を変えることによる文字起こし精度の変化を確認しました。
学習パラメータ
- エポック数:10
- バッチサイズ:1
- 学習率:1e-6
評価方法
一般的な音声認識精度と、学習した単語の認識精度の両方を測るため、以下の2種類の評価を行いました。
評価1:通常の音声データに対する認識精度
- WER(Word Error Rate):単語単位の誤り率
- CER(Character Error Rate):文字単位の誤り率
評価2:学習データの単語を含む音声データに対する認識精度
学習データセットに含まれる法人名100件に対して、法人名が含まれる音声データを筆者の声で収録しました。その音声データをモデルに与えて文字起こしを行い、正しく文字起こしできた割合で評価しました。
検証結果
学習データ数や学習率を変えてチューニングした結果を以下にまとめます。なお、使用するデータセットやベースモデルによっては異なる結果となる可能性があることをご了承ください。
単語はいくつまで学習させることができるのか
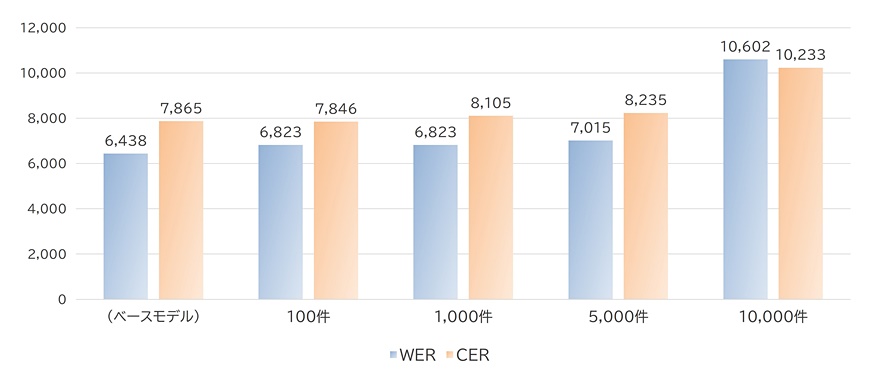
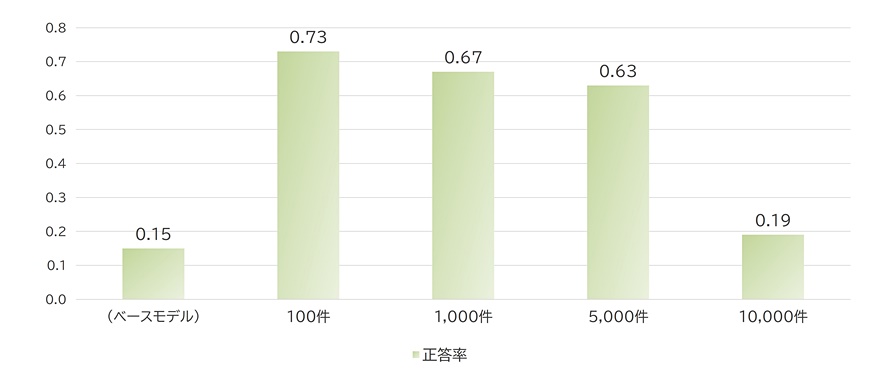
学習データ数を変えた場合の評価1、2の結果をそれぞれ以下の図2、3に示します。WERとCERは小さいほど精度が高いことを表し、正答率は多いほど学習データに含まれる単語が認識できるようになっていることを表します。
WERとCERは、どちらも学習データ数が多いほど数値が大きくなっています。これは、学習データを増やすほど、一般的な音声データに対する認識精度が低下することを示しています。5,000件まではベースモデルとそれほど差はありませんが、10,000件まで増やすと誤り率は1割を超えるレベルまで上昇しています。学習した単語の正答率も、データが増えるごとに低下しています。これは、Whisperは学習した単語全てを認識できるようになるわけではなく、学習データ数が多いほど効率は悪くなることを示しています。
このように、学習データ数を増やすほど精度は低下してしまいます。あまりに多くの単語を学習しようとすると既存の言語能力が失われたり、1単語あたりの定着率が低くなったりするようです。検証の結果、1,000件まではある程度問題なく学習できているので、Whisperチューニングを行う際は1,000件程度を上限の目安とすることがおすすめです。
チューニング後モデルはどのような誤りをすることが多いのか
評価2において、チューニング後のモデルがどのような誤り方をすることが多いかを、学習データ数1,000件のモデルを対象に調査しました。このモデルは評価データ100件に対して67件正答できていました。正答とならなかった33件の誤り方を分類した結果、特に多かった誤り方を表1に示します。ここでは、上位2件について紹介します。
最も多かったのは、漢字を同音の別の漢字に間違える、いわゆる誤変換でした。例えば、「東神貿易」を「東信貿易」に間違えるケースがありました。この誤りの原因としては、学習データセットの中に同音の別の単語が含まれていることが考えられます。東神貿易の例で言うと、学習データセットの中に「東信商事」や「東信テクニカ」といった法人名があったため、この影響を受けて正しく文字起こしできなかったとみられます。
次に多かったのは、アルファベットや記号をカタカナにしてしまうという誤りでした。例えば、「TJKリゾート」を「ティー・ジェー・ケー・リゾート」としてしまう誤りが見られました。このような誤りが多くなった理由としては、学習データの大半が日本語であることが考えられます。
| 分類 | 件数 |
|---|---|
| 漢字を同音の別の漢字に間違える | 7 |
| アルファベットや記号がカタカナになる | 5 |
| 拗音の大小(「キヤノン」が「キャノン」になるなど) | 4 |
| 法人名以外の箇所の誤り(「○○株式会社の佐藤です」の「佐藤」が「砂糖」になるなど) | 4 |
| 違う音の文字に間違える(「箸勝本店」が「八月本店」になるなど) | 4 |
表1 評価2における、チューニング後モデルの誤り分類結果(上位5件)
今回のように多くの単語を学習させる場合、言語の偏りが生じたり、他のデータにある単語の同音異義語となる単語を含んだりする場合が多くあります。このような場合、学習データセットの設計を見直す、文字起こし後に特定の文字列を置換する処理を実装する、などの対応が求められます。
まとめ
本稿では法人名を対象にした音声認識ツールWhisperのチューニングについて、実際の検証結果とともに紹介しました。Whisperをチューニングすることで、社内会議など固有名詞が多く現れる音声の文字起こしがより正確に実施できることが期待できます。Whisperの文字起こし精度についてお困りの方は、ぜひチューニングをお試しください。
-
※
Windowsは、米国Microsoft Corporationの、米国、日本およびその他の国における登録商標または商標です。
筆者紹介
新 隼人
R&D本部 言語処理技術部所属。言語処理技術に関する研究開発に従事。大規模言語モデル(生成AI)の業務活用に向けた研究やシステム開発に取り組む。