日本人なら知っておきたい! 生成AIの日本語理解力と賢い選び方テクニカルレポート
公開日:2025年7月23日
R&D本部言語処理技術部 シニアITアーキテクトの林です。今回は、生成AI(大規模言語モデル) の日本語理解能力と性能評価について、わかりやすく解説したいと思います。
生成AIの技術は急速に進化しており、ビジネスや日常生活での活用が広がっています。特に日本語対応の生成AIについては、「本当に日本語を正しく理解しているのか?」「どの生成AIを選べばよいのか?」といった疑問を持つ方も少なくないのではないでしょうか。
今、生成AIの日本語理解能力と性能評価について知っておくことは、生成AIを上手に使いこなすために重要です。生成AIの得意分野や限界を正しく理解することで、ビジネスや生活でより効果的に活用することが可能になります。この記事では、そんな生成AIの実力を客観的に判断するためのポイントを、簡潔にお伝えいたします。
なぜ、英語中心で学習した生成AIが日本語を理解できるのか?
生成AIは、膨大なテキストデータで学習します。多くの海外製の生成AIでは、学習に使われるデータの大部分が英語です。英語を中心に学習しているにもかかわらず、生成AIは日本語の質問にも答えられることがあります。
この疑問について、東京工業大学(現・東京科学大学)と産業技術総合研究所が調査を行いました。彼らの研究※1によると、生成AIは英語のデータだけでも日本語の一般知識や算術推論、プログラミングコードの生成に関しては学習できることがわかりました。
一方で、日本の文化や歴史、ビジネス習慣などに関する知識や、翻訳の能力を向上させるためには、日本語データをしっかり学習させる必要があるということも明らかになりました。
この研究は、日本語を理解する生成AIをつくる際に「どんな日本語のデータを学習させればいいのか?」という方向性を示しています。たとえば、日本の文化や歴史に関する文書、ビジネス用語を含むテキスト、日英翻訳の事例集などを活用することで、日本語をより理解できる生成AIが開発できると考えられています。
日本語対応の生成AIはどう開発されてきたのか?
OpenAIのChatGPTが登場して以来、その仕組みを解明したい、あるいはもっと日本語に強い生成AIを開発したいという動機から、大学や企業などでさまざまな生成AIがつくられてきました。
これらの生成AIのなかには、商用利用が可能なものも含め、誰でも使えるオープンなモデルも多く発表されています。開発の手法もさまざまで、最初から日本語のテキストだけで学習させたものや、英語で学習したモデルに日本語を追加学習させたものなど、さまざまなアプローチが取られています。
このように、日本語をより正確に理解し、活用できる生成AIを目指した研究と開発が、現在も活発に進められています。日本語を中心に学習した生成AIに関する情報は、こちら※2にまとまっています。2024年ごろからは1000億パラメータを超えるモデルも登場してきています。
生成AIをつくるには「性能評価」が欠かせない!
私たちが生成AIを使うとき、多くの人はOpenAIのGPT-4oやAnthropicのClaudeなど、一般的に「性能がよい」とされる生成AIを選ぶことが多いでしょう。「性能がよい」生成AIとはどういう生成AIなのでしょうか?
生成AIの評価方法は、とてもシンプルです。あらかじめ用意した「入力データ」と「正解データ」を使い、生成AIが出した回答がどれくらい正解データに近いかを測定することで、性能を評価します。この評価を通じて、生成AIが「どの程度の理解能力があるか」、「翻訳は得意なのか」などの指標が得られます。また、性能評価は生成AIを開発する際にも重要で、正しく学習できているかを確かめるためにも使われます。性能評価の結果をみて、生成AIの性能を改善していくことが可能になります。
このような性能評価をさまざまな基準で準備して生成AIの性能を評価し、それを比較できるようにまとめたものが「リーダーボード」と呼ばれるものです。
リーダーボード
生成AIの評価結果を一覧化し、ランキング形式で比較できるものをリーダーボードと呼びます。各生成AIは、さまざまな評価基準に基づいて測定され、その平均スコアによって順位が決まります。一般的には、ランキングの上位にある生成AIが高性能と判断されます。
評価スコアは通常 0〜1 の範囲で表されます。ただし、スコアが低いからといって必ずしも性能が悪いわけではありません。評価基準が厳しい場合には数値が低くなることもあるため、リーダーボードのスコアは相対的な比較に用いるのが適切です。たとえば、「この生成AIとあの生成AIはほぼ同じ性能」とか、「ある生成AIの平均スコアは低いが、読解能力はすぐれている」といった相対的な評価を行います。
下記は、一般公開されているリーダーボードの例です。
性能評価のポイント
生成AIの評価は、大きく3つの分野にわけられます。
- 1. 知識・能力評価
- 生成AIが質問に正しく答えられるか、知識や推論ができるかを測定します。
- 2. アライメント評価
- 生成AIが人間の意図や倫理観に沿った回答を生成しているかを確認します。
- 3. 安全性評価
- 危険な情報を提供しないか、公平性を保っているかをチェックします。
現在の性能評価は「① 知識・能力評価」が多く、とくに読解能力の評価が中心になっています。一方で、生成AIの文章作成能力などを適切に評価する基準もありますが、読解能力の評価ほど多くはありません。万能な評価は現在のところ存在しません。
また、生成AIは理論的な理解がまだ十分に進んでいません。そのため、評価する際には実際のデータと組み合わせたときによい結果が得られるかという道具的な観点が重要になります。具体的には、自分の業務やプロジェクトで使う入力データと正解データを準備し、それに対して最適な結果を出せる生成AIを選ぶ方法が効果的です。
単にチャットで利用するだけなら、リーダーボードの上位モデルを選ぶだけでも十分でしょう。しかし、要約をするなら要約が得意な生成AI、翻訳をするなら翻訳が得意な生成AIを選ぶべきです。その参考として、一般公開されているリーダーボードを参考にする方法もあります。ただし、リーダーボードの平均スコアを見るだけでなく、「この性能評価は翻訳に関する評価を行っており、スコアが高いから適している」など、正しい知識を持って判断することが大切です。また、生成AIを活用した製品開発や独自データでの追加学習を行う場合でも、実際の用途に応じた評価を行い、最適な生成AIを選ぶ視点を持つことが重要になります。
実際の性能評価
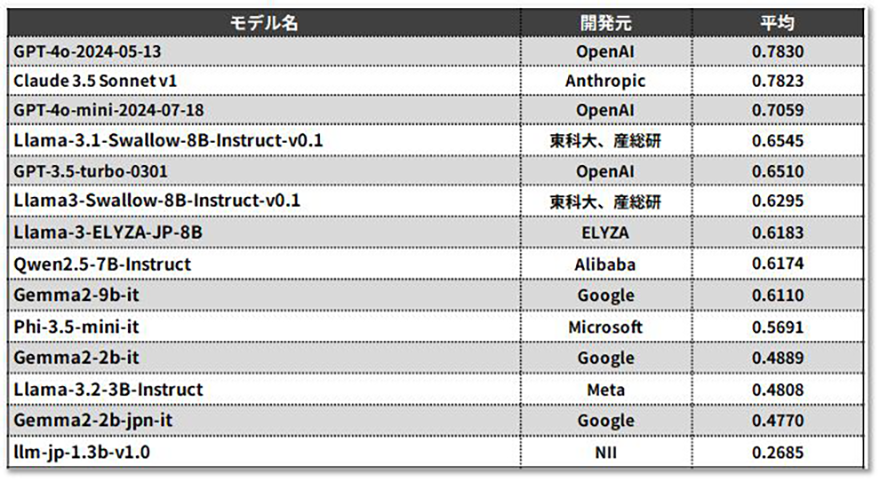
llm-jp-eval3というツールを使って、生成AIの性能を評価しました。llm-jp-evalは、国立情報学研究所を中心に国内の言語処理研究者が開発した日本語対応の性能評価ツールです。複数の日本語に特化したデータセットを用いて横断的に評価を行い、生成AIの日本語処理能力を測定します。
評価結果を簡単にまとめると、OpenAIのGPT-4oやAnthropicのClaudeは別格の性能を持っています。一方で、Llama3.1-Swallow-8BはChatGPTと同程度の実力があることがわかりました。また、Llama-3-ELYZA-JP-8Bは読解力がGPT-4oよりも高いため、要約などに適している可能性があります。

生成AIの日本語理解はさらに進化する!
生成AIの日本語理解能力と性能評価について解説しました。今後も、生成AIの日本語処理能力はさらに向上していくでしょう。新しい生成AIがどれだけ進化したのか、どの分野で活用できるのかを客観的に判断するために、性能評価を上手に活用してみてください。
筆者紹介

林 淑隆
R&D本部 言語処理技術部所属。言語処理技術や情報検索技術に関する研究開発、技術調査等に従事。大規模言語モデル(生成AI)自体の制御・運用に関する研究開発に取り組む。