生成AIの学習工程とビジネスにおける独自モデルの活用 テクニカルレポート

公開日:2026年1月8日
R&D本部 言語処理技術部 シニアITアーキテクトの林です。
生成系大規模言語モデル(生成AI)は、膨大なテキストデータを学習することで目覚ましい性能を発揮しました。一口に学習と言っても、生成AIの学習はいくつかの工程で構成されており、それぞれ特徴や目的があります。一方でオンプレミス環境において稼働する小さな生成AIの進化も顕著であり、自分たちのデータで独自に学習することも実現可能になっています。本稿では、生成AIの学習とは何か、独自に学習させた生成AIにはどのようなビジネスへの活用があるのかについて解説します。
生成AIの学習は、4つの工程から構成される
生成AIの学習は、基本的に次の4つの工程から構成されています(図1)。
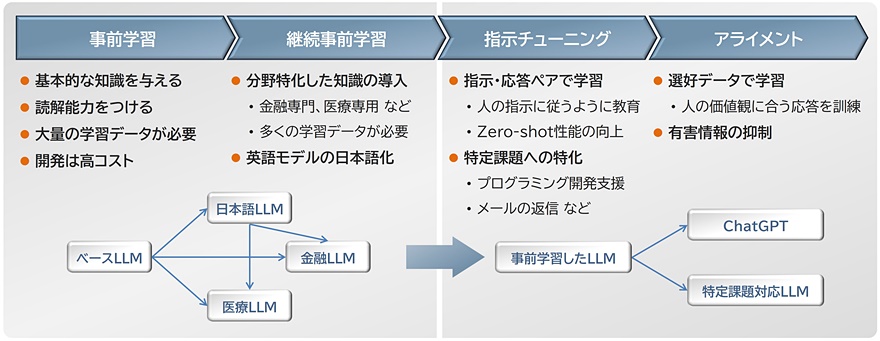
事前学習
基本的な知識や言語の読解能力をつけるための工程です。膨大なテキストデータを学習することで実現します。言語モデルのサイズが大きければ大きいほど性能が上がることがわかっているため、大量のメモリと高速な演算環境が必要となります。このため、一般的にはGPUクラスタを利用して学習するので、開発コストが非常に高いのが特徴です(数千万から数億円とも言われています)。事前学習済みの言語モデルとして、Meta社のLlama3-3.1-70B、国立情報学研究所のllm-jp-3-13B、などが公開されています。
継続事前学習
事前学習した言語モデルに対して、さらにデータを追加して事前学習を継続する工程です。例えば、分野に特化した知識を導入するために学習する(基本的な言語理解能力は、事前学習で学習済み)、あるいは、事前学習時に日本語を学習していない言語モデルに対して日本語を学習させるような工程になります。事前学習と同じく大量のテキストデータや計算環境は必要になりますが、ゼロから言語モデルを作成する手間はかかりません。
国内では、Meta社のLlamaに日本語の継続事前学習を行った言語モデルがいくつか公開されています(Llama 3.1 Swallow、Llama-3-ELYZA-JP 、など)。
指示チューニング
プロンプトで生成AIの性能を引き出すことはできますが、Zero-shot性能(参考事例を提示せずに生成AIの知識だけで回答させること=未知の課題に対する対応力)はよくありませんでした。この課題に対して、Zero-shot性能を向上させる目的で、事前学習した言語モデルに対して「指示」と「応答」の組み合わせを持つデータセットで訓練させる「指示チューニング」という研究※1が報告されました。指示チューニングによって、未知の課題に対する対応力が向上し、指示内容に沿った回答を生成するようになります。一般的に、指示チューニングは事前学習よりも開発コストが低いことが知られています。
図2に会話ができるように指示チューニングした例を示します。指示チューニングがあるとき、「こんにちは」の入力に対して「会話として呼びかけられた」と解釈し、その続きを「こんにちは、初めまして」と推測しています。一方で、指示チューニングをしていない場合は、同じように「こんにちは」と入力しても、会話ではなく、単純に言葉の続きとして推測して生成します。どちらも生成AIの基本原則である「次の語を推測する」に従っています。指示チューニングの有無で、その出力に変化があることがわかるでしょう。
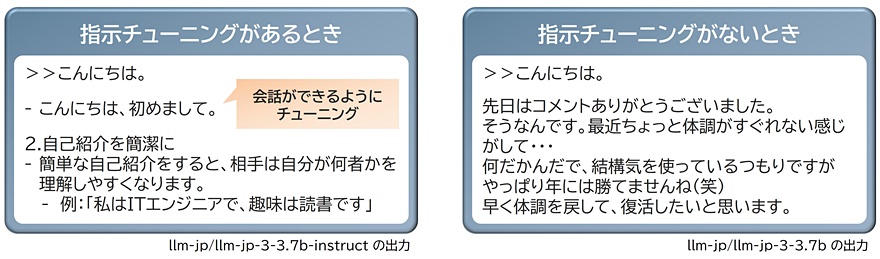
指示チューニングは、「指示」に対してこういう理想的な「応答」をしなさい、という教師あり学習になります。従って、同じ「指示」でも「応答」を変えることで、生成AIの挙動を変えられます。例えば、関西弁で応答させたり、メールの返信として応答させたり、などが考えられます。
また、プログラミング支援のような「こういうコードを書いてください」という指示に対して、プログラミングコードを出力する、といった課題解決への適用も考えられます。これらはプロンプト・エンジニアリングだけで対処することが難しい課題であるので、課題に応じて指示チューニングの実施を検討することになります。
-
※
J.Wei et al.,Finetuned Language Models Are Zero-Shot Learners ,2021
ただし、知識を増やす目的で指示チューニングを用いると、生成AIを壊すこともありますので、学習のやりすぎには注意が必要です。多くの外部知識に対応させたい場合は、継続事前学習の工程で対応する、もしくは、RAGの利用を検討することになります。特に外部知識が頻繁に更新されるような場合はRAGが適切でしょう。
指示チューニングは生成AIのパラメータを調整するため、生成AIのサイズに応じてGPUメモリが必要になります。学習時のメモリ使用量を抑えるための技術として、量子化やLoRA(Low-Rank Adaptation)、その両方を採用したQLoRA(Quantized Low-rank Adapter)といった技術が開発されています。
アライメント
生成AIの応答安全性や信頼性の向上を目的とした学習工程になります。人間の意図に沿わない内容や、不適切な出力を抑制する効果を狙います。プロンプトに対して好ましい応答と好ましくない応答を付与した選好データセットと呼ばれるデータで学習します。好ましい応答の生成確率を上げて、好ましくない応答の生成確率を下げる学習を行います。選好データの例としては、「〇〇さんの住所を教えて!」に対して、「できません」が好ましい応答で、「もちろんです!〇〇県の・・・」が好ましくない応答です。
指示チューニングは「指示」に対して理想的な「応答」を返すように学習させたいので、学習データの作成に人的コストがかかります。一方で選好データの作成は、既存の生成AIを使って複数の応答を作成し、その優劣のみ判断すればよいので、指示チューニング向けのデータセットに比べて開発コストが低くなる傾向があります。また負のフィードバックを明示的に与えられることも利点となります(前述の住所の事例)。生成AIが持っていない知識に対して虚偽の応答をするハルシネーションの抑制にも効果があるとされています。
独自に学習した生成AIをビジネスへ活用する
生成AIをビジネスで活用する場合、GPT-5やClaudeなどのクラウドサービスを利用することが一般的です。クラウドサービス上の生成AIは最新/高性能であり、簡単な課題なら顧客だけで解決できる時代になりつつあります。一方で、オンプレミス環境で稼働する小さな生成AIも開発され、その性能は2022年に発表された当時のChatGPTとほぼ同等の性能を持つようになり、スマートフォンで稼働できるサイズのものも存在しています。このような技術進化は、これからも加速的に進んでいくでしょう。
社内データで学習した生成AIを利用したいが社外にデータを出したくないといったニーズや、プロンプト・エンジニアリングでは対応が難しい課題も顕在化しつつあります。このような課題を解決するために、小さな生成AIに対して、独自データでチューニングした生成AIを利用するという方法は、課題解決の選択肢のひとつになってきている、と考えてよいでしょう。
課題に特化した生成AIの提供で他社優位性を
- プロンプト・エンジニアリングでは対応が難しいような課題
- 分野に特化した知識が必要となるような課題
- クラウドサービスに出したくないドキュメントで生成AIを利用したいような課題
- 単一の課題を解くことにだけ特化した生成AI(翻訳しかしない小さな生成AI、など)
AIエージェントの要素技術として
- 簡単な課題はオンプレミス環境下の生成AIですばやく対応
- 業務特化した支援をするための小さな言語モデルをエージェントのバックエンドに
プログラミングコードの開発支援として
- 社内の既存コードを学習させたプログラミング支援モデルの開発
- テスターやコードレビューアとしての生成AIの活用
まとめ
生成AIは4つの学習工程を経て、その性能を実現していることを解説しました。この学習工程を通じて、企業は独自データを活用したカスタマイズモデルの開発ができるようになります。また、小さな生成AIを活用してオンプレミス環境下で運用することも可能になっています。このように、特定の課題解決や業務支援において、生成AIのビジネス活用がますます広がっており、今後も新たな可能性が期待されます。
筆者紹介

林 淑隆
R&D本部 言語処理技術部所属。言語処理技術や情報検索技術に関する研究開発、技術調査等に従事。大規模言語モデル(生成AI)自体の制御/運用に関する研究開発に取り組む。