ディープラーニングの得意領域コラム
公開日:2024年4月3日

2022年11月にOpenAI社からリリースされたChatGPTによって生成系AIに対する注目度が大きく上がりました。AI関連株として注目される米大手NVIDIA社の株価も急騰しています。もっとも、AIブームは近年急に始まったものではなく、これまでにも話題になることは何度もありました。しかし、誰もが気軽に試せるChatGPTやStable Diffusionなどの登場によってAIが多くの人々にとって身近な存在になったのはごく最近のことと言えます。今回は、これらのサービスに使われている技術、「ディープラーニング」を取り上げます。
目次
-
ディープラーニングの特徴
-
ⅰデータの特徴量抽出方法
-
ⅱディープラーニングの得意領域
-
ⅲディープラーニングが使用される主な分野
-
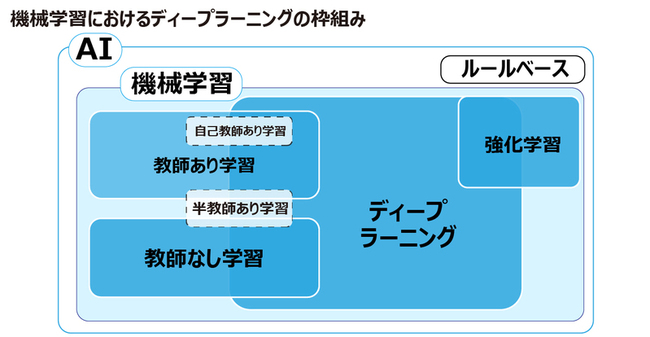
1.AIにおけるディープラーニングの位置づけ
まずはじめに、ディープラーニングについて紹介する前にAI、機械学習について説明します。
AIという言葉は幅広い意味で使われますが、人の知能を模倣する技術やシステムのことを指します。後述する機械学習や、人がルールを決めて運用するルールベースなども該当します。
続いて、機械学習とは、アルゴリズムがデータから学習し、データから特徴や知識を抽出する技術となります。
アルゴリズムがデータから学習する主な手法は、教師あり学習、教師なし学習、半教師あり学習、強化学習、自己教師あり学習です。それぞれの特徴は以下の通りです。
- 教師あり学習
- アルゴリズムが教師ラベルという正解データと照らし合わせながら学習し、データから特徴を捉える学習方法です。幅広いテーマに適用することができる学習方法です。
- 教師なし学習
-
教師ラベルがないデータから特徴を捉える学習方法であり、異常検知やクラスタリングといったテーマで使用されます。
教師なし学習は、ラベル付けされていないデータを活用でき、データ内のパターンや構造を発見するのに役立ちます。ただし、正解データが用意できる場合は、精度向上の目指しやすさや、モデル検証の難易度が下がるといった点から、教師あり学習を選択する方が望ましいです。
- 半教師あり学習
- 教師ラベルが付いているデータと教師ラベルが付いていないデータから、特徴を捉える学習方法です。教師あり学習と教師なし学習の中間にあたる学習手法で、教師ラベルが付いていないデータも使用することで、大規模なデータセットから情報を引き出すことができます。教師ラベルが付いていないデータから適切な情報を引き抜く難しさが課題となります。
- 強化学習
- 強化学習は、エージェントが未知の環境と対話しながら、与えられたタスクにおいて報酬を最大化するための方策を学習する機械学習の方法です。この手法では、エージェントは環境からの観測を受け取り、その観測に基づいて行動を選択します。そして、その行動によって環境が変化し、エージェントはその結果として報酬を受け取ります。
- 自己教師あり学習
-
教師あり学習の一種であり、教師ラベル付きのデータを使用せずにモデルを学習する方法です。自己教師あり学習では、入力データ自体が教師(正解)として機能します。
自己教師あり学習は、ラベル付けされたデータが不足している問題や、ラベル付けが困難な問題において有用です。
LLM(Large Language Models)では、これを利用して学習することが一般的です。
そして、ディープラーニングについてです。ディープラーニングは、多層のニューラルネットワークを使用して、データから特徴を学習する機械学習の一分野です。 ニューラルネットワークとは、生物学的な神経細胞の仕組みに着想を得た数学的モデルであり、神経細胞を模倣した数理技術になります。
この多層のニューラルネットワークを使用していた場合にディープラーニングと呼ばれます。
ディープラーニングには、さまざまなアルゴリズムや手法が存在しますが、教師あり学習、教師なし学習などによって学習します。
ここまで、AI、機械学習、ディープラーニングの概要をご説明しました。ここからはディープラーニングの特徴について紹介していきます
2.ディープラーニングの特徴
ⅰ データの特徴量抽出方法
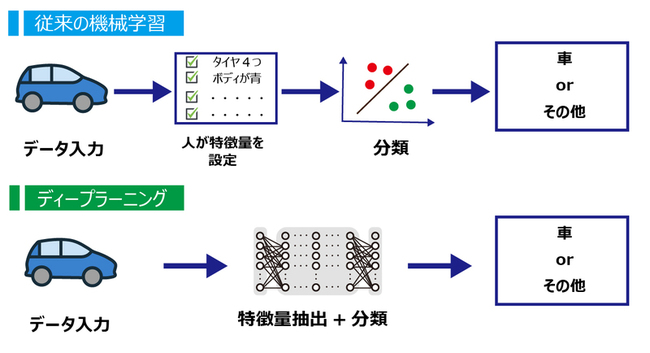
教師あり学習でよく使用されるGBDT系アルゴリズムなど※1では、特徴量エンジニアリングが重要であり、人の手で設計された特徴を使用してモデルを構築します。そのため、ドメイン知識が非常に重要となります。一方、ディープラーニングでは特徴抽出のステップがアルゴリズム内で組み込まれているため、モデルがデータから自動的に特徴を抽出します。また、ディープラーニングはエンドツーエンドで学習するため、出力も全て自動で行います。GBDT系アルゴリズムなどの機械学習では特徴量エンジニアリングに重点を置き、人が特定の特徴を手動で設計する必要があります。対して、ディープラーニングでは、特徴の自動抽出とエンドツーエンドの学習に重点を置いています。
-
※1
GBDT系アルゴリズムとは勾配ブースティング決定木と呼ばれる機械学習アルゴリズムの一種です。表形式の構造化データの学習に特化したアルゴリズムで、商品の需要予測や、顧客セグメンテーションなどの分類問題に強いアルゴリズムとなります。代表的なアルゴリズムではXGBoost、LightGBMなどが挙げられます。
ⅱ ディープラーニングの得意領域
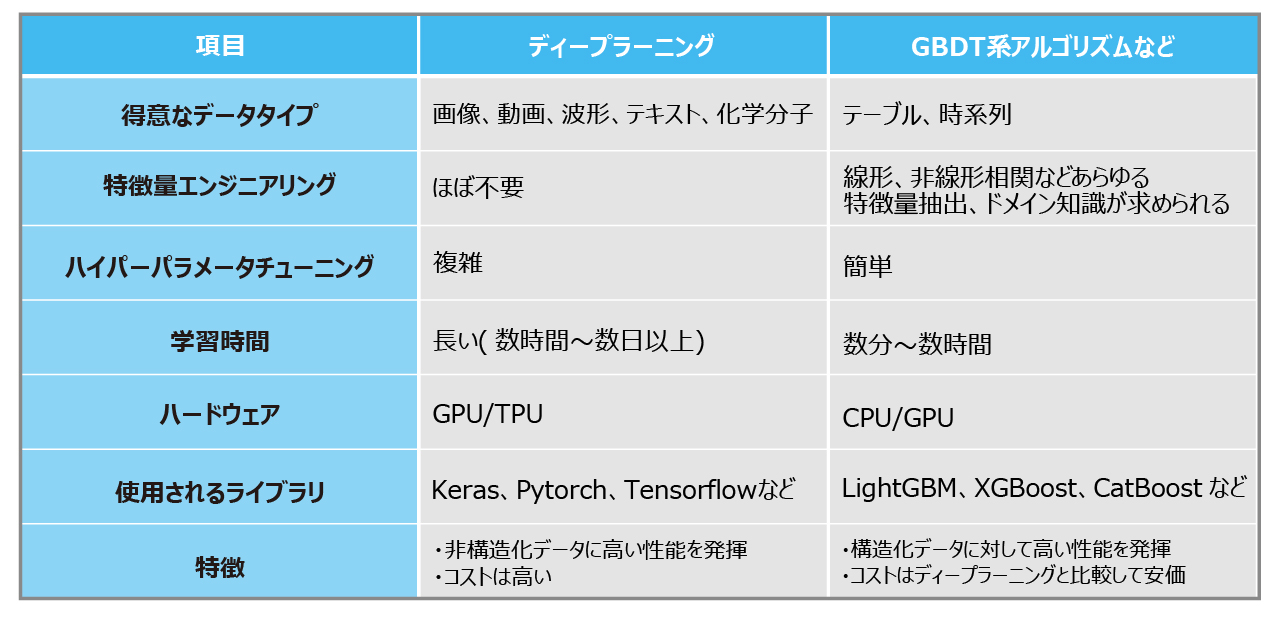
GBDT系アルゴリズムの機械学習とディープラーニングの違いについては先述の通りですが、どのような場合でもディープラーニングをすれば良いという訳ではありません。基本的にディープラーニングはより多くのデータ数が必要であり、モデルの精度を出すためにはハイパーパラメータの調整が欠かせません。GBDT系アルゴリズムの機械学習にもハイパーパラメータの調整はありますが、ディープラーニングではその及ぼす影響が大きく複雑です。また、計算コストも膨大なものとなります。そのため、目的に応じてGBDT系アルゴリズムなどの機械学習を選択するか、ディープラーニングを選択するかを判断しなければなりません。
なお、ディープラーニングが威力を発揮するのは非構造化データ(画像、言語、音声など)を扱う際であり、非構造化データの特徴を抽出するのに有用な手法となります。表形式の構造化データでもディープラーニングは実施可能ですが、従来の機械学習となるGBDT系アルゴリズムなどを使用した方が容易にモデルを作成でき、学習時間も短い可能性が高いです。
ⅲ ディープラーニングが使用される主な分野
ディープラーニングでは、多様なアルゴリズムを駆使して、多彩な表現が可能です。そのため、さまざまなタスクでディープラーニングの適用が可能です。
- 画像認識
-
物体検出、セグメンテーションなどの分野で幅広く利用されています。
物体検出は、画像内の物体の位置とクラスを特定するタスクです。このタスクでは、画像内に複数の物体が存在し、それぞれの物体の位置と種類を検出する必要があります。物体検出は、自動運転、監視カメラ、画像検索、ロボット工学などのさまざまな領域で利用されています。一般的なアプローチには、Faster R-CNN、YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)などがあります。
セグメンテーションは、画像内のピクセルレベルで物体を識別するタスクです。つまり、画像内の各ピクセルを物体に割り当てる必要があります。セグメンテーションは、医療画像処理、自動車の画像解析、地理情報システム(GIS)、農業などの分野で広く利用されています。セグメンテーションの主なアプローチには、FCN(Fully Convolutional Network)、U-Net、Mask R-CNNなどがあります。
- 音声処理
-
音声認識、音声合成などの音声関連タスクにおいて成果を挙げています。2023年にはビートルズの最新曲が発売され、話題となりました。
音声認識は、話者が発話した音声を文字やコマンドなどのテキスト形式に変換するタスクです。音声検索、音声アシスタント(例: Siri、Alexa、Googleアシスタントなど)、自動字幕生成、医療文書の記述などの分野で広く利用されています。最近のディープラーニングベースの音声認識システムは、リカレントニューラルネットワーク(RNN)やトランスフォーマーなどのモデルを使用して、高い精度を実現しています。
音声合成は、テキストから音声を生成する技術であり、合成された音声は自然な話し声に聞こえるように設計されます。ナビゲーションシステム、読み上げアプリ、自動応答システム、ロボットの音声などの分野で使用されています。ディープラーニングを用いた音声合成システムでは、WaveNetやTacotronなどのニューラルネットワークアーキテクチャが使用され、より自然な音声の生成が可能になっています。
- 自然言語処理
-
機械翻訳、感情分析などの自然言語処理タスクにおいて効果的に利用されています。
機械翻訳は、ある言語のテキストを別の言語に自動的に翻訳するタスクです。このタスクでは、入力文と出力文の間の意味の対応を理解し、適切な翻訳を生成する必要があります。ディープラーニングを用いたニューラル機械翻訳モデルは、近年、言語間の翻訳品質を大幅に向上させました。
感情分析は、テキストデータの感情や意見を判定するタスクです。具体的には、テキスト内の感情的なニュアンスや態度を分析し、ポジティブ、ネガティブ、または中立といった感情を推定します。感情分析は、ソーシャルメディアのユーザーの感情を把握すること、製品レビューやフィードバックの分析などに活用されます。
- 生成系
- ChatGPT、Stable Diffusionなどの生成系AIもディープラーニング技術であり、進化が目覚ましい分野となります。生成系AIモデルは、与えられた入力に基づいて新しいデータを生成する能力を持ち、自然言語、画像、音声などのさまざまなタイプのデータを生成できます。
3.最後に
今回のコラムでは、ディープラーニングを中心に取り上げました。
ChatGPTを始めとするディープラーニングの分野は、先述の通り、注目度が非常に高い分野で、今後も技術が発展していくことは容易に想像がつきます。そのため当社としても力を入れている分野となります。
今回はディープラーニングに関する一般的な解説が中心でしたが、次回以降、より技術的に踏み込んだ内容や、当社のディープラーニングに関する具体的な取り組みについてもご紹介する予定です。
筆者紹介

大橋 俊貴(おおはし としき)キヤノンITソリューションズ株式会社 デジタルビジネス統括本部デジタルソリューション開発本部 デジタルビジネス推進部
<略歴>
2017年鉄道会社に勤務。
変電所でのデータ分析に従事し、回生エネルギーを有効活用しての駅の負荷低減などの活動を実施。
2021年キヤノンITソリューションズ入社。顧客のデータを預かり、データサイエンティストとして分析や機械学習を用いた予測システム構築などの業務に励む。
関連するソリューション・製品
- AI(人工知能)
- AIの活用が進み、AIを使ったソリューションが身近になる一方、実用化にまで至らないAIプロジェクトも数多く存在します。
キヤノンITソリューションズでは、長年にわたるSIerとしての経験と業務知識、さらにはR&D部門での研究によって得た知識や、商品開発の技術を駆使して、お客さまの課題解決にAIを活用した支援を行います。
- データマネジメントサービス
-
消費者ニーズやビジネス市場の変化に柔軟に対応するためには「データ活用」が必要です。そのデータ活用には、データとデータを活かせる人材が重要です。ビジネス変革に効果的なデータ活用には、活用の目的に沿ったデータを整備し、そのデータを蓄積する仕組みを作る必要があります。かつデータを分析しインサイト(本質を突いた気付きや洞察)を得るためのデジタル人材が欠かせません。
キヤノンITソリューションズは、データを整備・活用する仕組みを構築し、「価値あるデータ」と「データを活かせる人材(デジタル人材)」の創造を『データマネジメントサービス』として提供することで、お客さまのDX実現を支援します。
- 機械学習入門講座
- 機械学習のスキル習得には、データモデリングやプログラミングの知識のみならず、膨大なデータから得たアウトプットを元にビジネスアイディアを創出するスキルが重要です。キヤノンITソリューションズの機械学習入門講座では、テクニカルな要素はツールに任せ、「機械学習を身近に感じていただく」「機械学習を通じてビジネスを変革する素養を身に付ける」ことをコンセプトに、お客さまのDX内製化ご支援のためのカリキュラムを提供しています。