![]()
順位学習
- Tech & Quality Report
- キヤノンITソリューションズが、これまで数多くのシステム開発によって培ってきた経験と品質向上への取り組みにより、お客さまの業務課題を解決した好事例や研究の成果をご紹介します。
類似検索のさらなる精度向上を目指して
近年、人工知能関連技術の進展が著しく「第3次人工知能ブーム」といわれて脚光を浴びている。当社R&D本部でも画像認識、自然言語処理などの分野で人工知能に関するさまざまな研究を推進しており、その1つに「順位学習」がある。「順位学習」とは、類似検索に機械学習を適用することで、さらに検索精度を向上させる技術である。本稿ではR&D本部における順位学習への取り組みの概要を紹介する。
文書の類似検索
企業には大量の非定型な文書情報が存在する。例えばコールセンターが問い合わせを受け付けると、顧客名、製品名、日付などの項目をルールに従った形式で記録する定型データだけではなく、問い合わせの内容が自由記述の文書として残される。また業種にかかわらず社内規定や社員への通知などが自然言語で記載され、自由記述の文書として蓄積されている。
類似検索自体はさほど新しい技術ではなく1990年代には既に商用化され、検索条件を比較的柔軟に指定できることなどからさまざまな場面で利用されてきた。Webサイトの検索でも同様だが、望んでいる情報にたどり着くには非常に苦労することがある。必要な情報を見つけるために、検索結果一覧を大量にたどったことはないだろうか?それでも見つからず、何度も検索条件を入れ直したことはないだろうか?
実は、類似検索は自然言語処理と統計処理を利用している。検索対象となる文書をあらかじめ解析して出現した単語を統計処理し、単語の重要度を数値化しておく。検索時にはヒットした各文書がどの程度重要な単語を含むかを基に、文書のスコアを計算する。
ところが決まり切った手順で処理を実行するのだから検索対象と検索条件が同じである限り、同じ結果しか得られない。すなわち、検索者の意図が全く異なる場合であっても、検索条件が同じであれば同じ結果となる。そこで検索者が望む検索結果を得るためには、検索者の意図を含んだデータで学習し、検索時にはその学習結果によるランクの調整(再ランク付け)が必要となる。この技術を順位学習という。
順位学習概要
前述したように順位学習のためには、まず学習データが必要である。学習データとは、検索者の入力した「検索条件」と、検索結果一覧の中から検索者が「この文書(情報)が欲しかったのだ」と対応をつけた「正解」からなるデータを集めたものである。企業の製品のFAQサイトでも「この情報は役に立った」などをチェックし、ログを保存しているケースがあるが、このような検索ログも検索条件と正解となる文書が対応づけられていれば、学習データとして利用することが可能である。
順位学習における学習と検索の流れを図1により簡単に説明する。まず実際に検索する前に学習データ(①)を用いて学習モデル(②)を生成する必要がある。
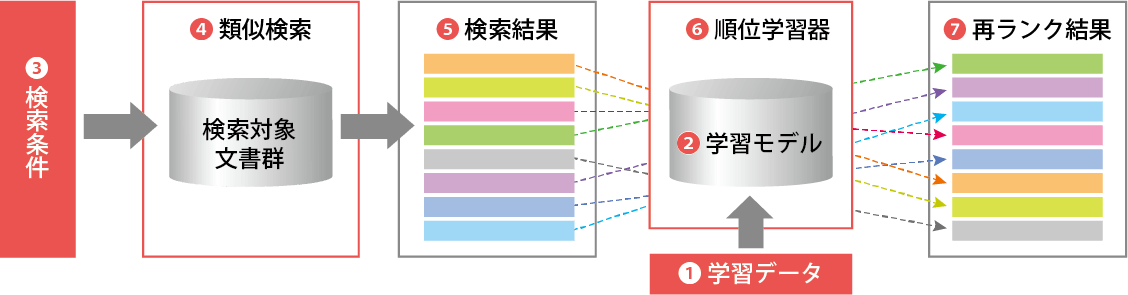
前述の通り学習データ(①)には、検索条件と対応する正解となる文書が特定されているので、順位学習器(⑥)は言語的にさまざまな観点で両者を解析、比較し、その特徴を数値化する。同様に検索条件と正解ではない文書も比較し、数値化する。
学習データは大量にあるので、正解あるいは不正解に対応づけられた数値が大量に得られるが、数学的手法でこれらの正解と不正解の数値を分ける「境界」を見つける。これが生成された学習モデル(②)である。
次に、実際に検索者が入力した条件に対し、学習モデルを利用してどのようにもっともらしい結果を返すのかを説明する。検索条件(③)を入力すると、前章で説明した類似検索で文書群を検索し(④)、結果を返す(⑤)。この検索結果(⑤)を学習モデルの生成に用いたときと同じ順位学習器(⑥)に渡す。
順位学習器(⑥)は渡された検索結果の中からいずれが検索条件に対して「正解」らしいか、を推定しなければならない。
実際の検索では、当然「正解」は分かっていないが、検索条件(③)と各々の検索結果(⑤)を学習モデル生成時と同じ処理で数値化し、学習モデル(②)と比較して「正解と不正解の境界」のどちら側にあるかを判定していくことができる。それにより、検索結果を1つずつ正解であるか否か推定していく。また正解側にある文書同士でも境界から離れているほど(正解領域の奥深くにあるほど)より正解である可能性が高いと推定することで再ランク付けを行う(⑥、⑦)。以上が検索時の処理である。
順位学習の改良によるさらなる精度向上
実は我々は当初、他社が実装した複数の順位学習器(以下他社実装という)を評価していた。社内にあるFAQなどの文書群を幾つか事例として評価したが、思ったような精度向上が得られない場合もあり、R&D本部における順位学習器の独自開発に踏み切った。
ところが独自開発した当初の順位学習器は、他社実装とほぼ同様の精度であった。調査の結果、精度が向上しない原因は2つあった。
1つ目は検索対象となる文書側の問題である。例えば「ソフトウェアのある機能が上手く動作しない」との問い合わせに対しては、操作手順以外にも前提となるパソコン設定やネットワーク設定などの説明が含まれていることがある。このように同一の文書内にさまざまな情報が含まれると言語的な特徴がぼやけてしまうため検索精度は向上しない。
2つ目は検索条件と検索対象文書の言語的な特徴の差である。検索対象となる文書の作成者はその分野の専門家であるが、検索者は非専門家であるといったケースが多くあり、使用する単語や言い回しに違いが生じる。単語については同義語/関連語辞書を用いてある程度は解決できるが、ケースにより異なる。
前述の2つの原因とは別に、学習データの量も重要である。正解となる情報を検索者に指定してもらうのが一番良いのだが、期待するほど学習データが集まらないケースもある。学習データを自動的に増やす研究もあるが、闇雲に増やすと学習時間が指数関数的に長くなり、実用的ではなくなる。
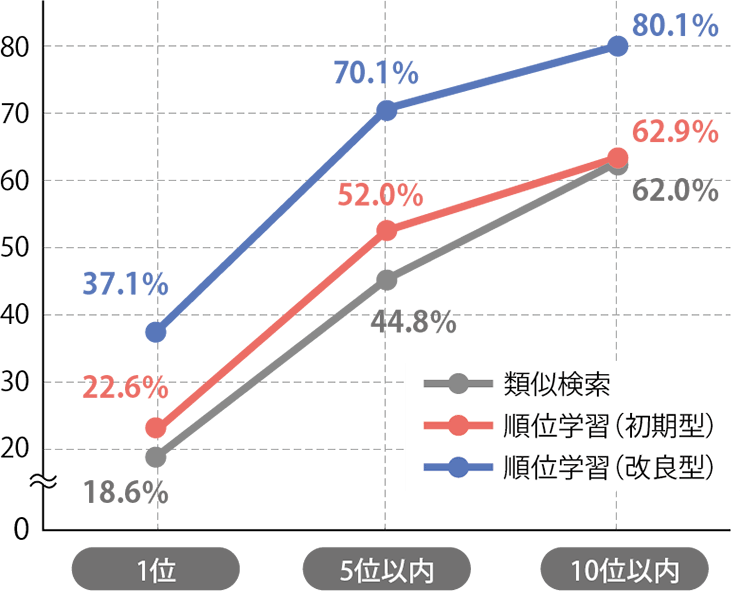
以上を踏まえて検討と評価を繰り返し、我々は最終的に、学習モデル生成時に学習データから得られる言語的特徴を検索者の生の言葉として検索対象文書に追加することで、比較的少ない学習データでも精度向上を実現する「順位学習の改良型」を開発した。その結果を図2のグラフに示す。当社製品の実際のFAQと、検索ログを学習データとして用いた評価である。
{kind=link}
{kind=link}
グラフは評価用検索条件で検索した際、事前に正解とされている文書が指定の順位までに出現する確率を表したものである。例えば、未学習の類似検索(黒い折れ線)では正解が5位以内に出現する確率は44.8%だったのに対して、改良型(青い折れ線)では70.1%と25ポイント以上向上している。
改良型の順位学習器で学習した精度は、未学習との比較では18~25ポイント、独自開発当初の順位学習器(赤い折れ線)との比較で15~18ポイント程度向上している。
最後に

キヤノンITソリューションズ株式会社
R&D本部
オブジェクト指向技術部
下郡山 敬己
Hiroki Shimokooriyama
精度が向上した我々の改良型の順位学習器により、他社実装に対する優位性を持つことができたと考えている。
今後、実際のシステムへの導入を通してさらに精度を高め、また使いやすさを向上させるための技術開発に取り組んでいく所存である。
※ 記事中のデータ、人物の所属・役職などは、記事掲載当時のものです。